Hexagonal architecture
Ports and adapters
Matteo Galacci
Freelance Back-end developer
e Consulente allo sviluppo
Github: https://github.com/matiux
Slack: matiux
Email: m.galacci@gmail.com
Linkedin: Matteo Galacci
aka

https://github.com/matiux/hexagonal-architecture
Introduzione
Alistair Cockburn (noto come uno degli iniziatori del movimento agile nello sviluppo del software) nel 2005 presenta l’hexagonal architecture come soluzione ai problemi di layering tradizionali e coupling. Hexagonal architecture abbraccia temi come il disaccoppiamento del codice dal framework, lasciando che la nostra applicazione si esprima, usando un framework come mezzo per svolgere compiti nella nostra applicazione, invece di essere la nostra applicazione stessa.
Allow an application to equally be driven by users, programs, automated test or batch scripts, and to be developed and tested in isolation from its eventual run-time devices and databases.
L'idea è di pensare alla nostra applicazione come artefatto centrale di un sistema, in cui tutti gli input e gli output raggiungono / lasciano l'applicazione attraverso una porta che isola l'applicazione da strumenti esterni. L'applicazione non dovrebbe avere alcuna conoscenza di chi / cosa sta inviando input o ricevendo il suo output. Questo ha lo scopo di fornire una certa protezione contro l'evoluzione della tecnologia e dei requisiti aziendali.
ARCHITETTURA in generale
-
High maintainability
-
Low technical debt
La manutenibilità è l'assenza (riduzione) del debito tecnico. Un'applicazione mantenibile è quella che aumenta il debito tecnico al ritmo più lento che possiamo raggiungere con la massima facilità. All’inizio le applicazioni sono facili da gestire, ma poi crescono. Una buona architettura all'inizio di un progetto può aiutare a prevenire tali problemi.
-
Le modifiche in un'area di un'applicazione dovrebbero interessare il minor numero possibile di aree.
-
L'aggiunta di funzionalità non dovrebbe richiedere modifiche a grandi aree di codice. Idealmente a nessuna.
-
L'aggiunta di nuovi modi per interagire con l'applicazione dovrebbe richiedere il minor numero possibile di modifiche.
-
Il debug dovrebbe richiedere il minor numero possibile di work-around.
-
I test dovrebbero essere relativamente facili. (Quando il codice inizia a sembrarci difficile, forse è il caso di fermarci e farci delle domande)
Manutenibilità
ARCHITETTURA in generale
DEbito tecnico
Il debito tecnico è il debito che paghiamo per le nostre (cattive) decisioni, ed è ripagato nel tempo e nella frustrazione. Per ogni decisione sbagliata, finiamo per creare work-around e hack.
Identify the aspects of your application that vary and separate them from what stays the same.
Perchè?
Ogni software è composto da due parti, il comportamento è la struttura e spesso ci si concentra troppo su uno a discapito dell’altro. Parlando con un manager ci dirà sempre che le funzionalità sono primarie, e spesso gli sviluppatori si adeguano a questa condizione.
- Un programma che funziona perfettamente ma difficile (o impossibile) da modificare, non funzionerà più quando cambieranno i requisiti. Il programma diventa inutile.
- Un programma che non funziona ma facile da modificare lo si può far funzionare e potrà farlo funzionare anche quando i requisiti cambieranno.
Interrompere la modalità di apprendimento basata su Framework dedicandosi ai principi corretti per uno sviluppo pulito e ben strutturato.
Robert C. Martin
Perchè?
| la Matrice di eisenhower
“Ho due tipi di problemi: l’urgenza e l’importante. L’urgente non è importante, e l’importante non è mai urgente”
|
1. Urgente e importante attività da eseguire al più presto e di persona |
2. Non urgente e importante attività a cui porre una scadenza e da eseguire personalmente |
|
3. Urgente e non importante attività da delegare se possibile |
4. Non urgente e non importante attività da eliminare |
-
Il primo valore del software, il comportamento, _è urgente_, ma non sempre particolarmente importante.
-
Il secondo valore del software, l’architettura, non è mai urgente, ma _è importante_.
Classifica delle priorità della matrice
-
urgente e importante (comportamento / architettura)
-
non urgente e importante (architettura)
-
urgente e non importante (comportamento)
-
non urgente e non importante
Robert C. Martin
Perchè?
L’architettura del codice, che è importante, è nelle prime due posizione, mentre il comportamento occupa la prima e la terza posizione. L’errore che spesso fanno i manager è di elevare ciò che è alla posizione 3, alla posizione 1, ossia sbagliano nel separare le funzionalità che sono urgenti ma non importanti da quelle che invece sono davvero urgenti e importanti. E così si finisce con il sacrificare l’architettura del sistema a favore di funzionalità non così importanti. Il problema per gli sviluppatori è che i manager non sono in grado di valutare l’importanza dell’architettura. A quello devono pensare loro, gli sviluppatori.
| la Matrice di eisenhower
Robert C. Martin
Se l’architettura verrà per ultima lo sviluppo del del sistema diventerà sempre più costoso e alla fine ogni modifica diventerà praticamente impossibile anche su una singola parte del sistema.
Classifica delle priorità della matrice
-
urgente e importante (comportamento / architettura)
-
non urgente e importante (architettura)
-
urgente e non importante (comportamento)
-
non urgente e non importante
PORTS AND ADAPTER
L’Hexagonal Architecture è un'architettura a strati, viene anche chiamata architettura Ports and Adapters. Questo perché evidenzia il concetto di "porte" differenti, che possono essere adattate per ogni livello. Ci invita a descrivere un'applicazione in più livelli al fine di creare divisioni concettuali tra le aree funzionali di un'applicazione. Il codice all'interno dei livelli (e i loro confini) dovrebbe descrivere come i layers comunicano tra loro. Poiché gli strati fungono da Ports e Adapters per gli altri layers interni e circostanti, è importante descrivere la comunicazione tra loro.
Ogni livello ha due elementi:
-
Code: Il codice all'interno di un livello è codice reale e fa cose. Spesso questo codice funge da Adapter per le porte definite in altri livelli, ma può anche essere qualsiasi codice di cui abbiamo bisogno (Business logic o altri servizi).
-
Boundary: Ogni livello ha anche un confine tra se stesso e uno strato esterno. Al confine troviamo le nostre Ports. Queste porte sono interfacce definite dal livello e definiscono come i livelli esterni possono comunicare con il livello corrente.
PORTS AND ADAPTER
| evoluzione
Già nel Nel 2005 si sapeva che ciò che è veramente rilevante in un sistema sono gli strati interni. Questi livelli sono quelli in cui tutta la logica aziendale vive, sono la vera differenza rispetto ai nostri concorrenti. Questa è la vera "applicazione" (Business logic).
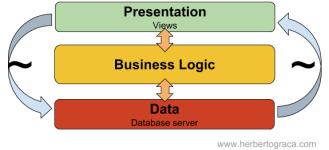
Ma a un certo punto, Alistair Cockburn si rese conto che gli strati superiori e inferiori, erano semplicemente punti di entrata / uscita - da / per l'applicazione. Sebbene siano in realtà diversi, hanno comunque obiettivi molto simili e c'è simmetria nel design. Inoltre, se vogliamo isolare i nostri strati interni dell'applicazione, possiamo farlo usando quei punti di entrata / uscita, in modo simile.
PORTS AND ADAPTER
| evoluzione
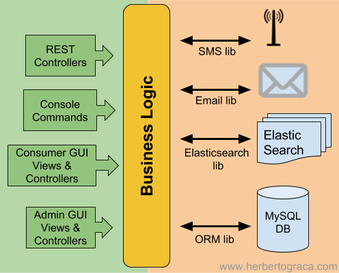
Sebbene possiamo identificare due lati simmetrici dell'applicazione, ogni lato può avere diversi punti di entrata / uscita. Ad esempio, un'API e un'interfaccia utente sono due punti di ingresso / uscita diversi sul lato sinistro dell'applicazione, mentre un ORM e un motore di ricerca sono due punti di ingresso / uscita diversi sul lato destro della nostra applicazione. Per rappresentare che la nostra applicazione ha diversi punti di entrata / uscita, disegneremo il nostro diagramma di applicazione con più lati. Il diagramma poteva essere qualsiasi poligono con più lati, ma la scelta si è rivelata un esagono. Da qui il nome "Architettura esagonale".
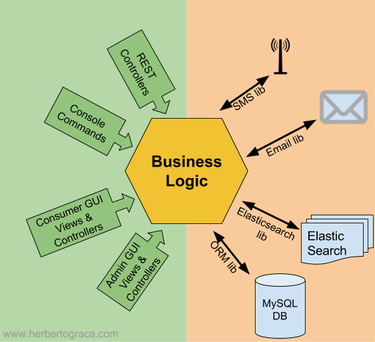
PORTS AND ADAPTER
| PorT
Una porta è un punto di ingresso / uscita agnostico da e per l'applicazione. In molte linguaggi, sarà un'interfaccia. Ad esempio, può essere un'interfaccia utilizzata per eseguire ricerche in un motore di ricerca. Nella nostra applicazione, useremo questa interfaccia come un punto di ingresso e / o di uscita senza alcuna conoscenza dell'implementazione concreta che verrà effettivamente iniettata dove l'interfaccia è definita come un suggerimento sul tipo (Type hinting).
Una porta può essere pensata come un vettore per accettare richieste (o dati) in un'applicazione. Ad esempio, una porta HTTP (richieste browser, API) può effettuare richieste sulla nostra applicazione. Allo stesso modo, anche un queue worker può fare una richiesta sulla nostra applicazione. Queste sono porte diverse nella nostra applicazione, ma fanno anche parte della "porta di richiesta".
PORTS AND ADAPTER
| Adapter
Per ognuna delle porte definite abbiamo bisogno di un codice per far funzionare davvero la connessione. Ad esempio abbiamo bisogno del codice per gestire i messaggi HTTP per consentire agli utenti di parlare con la nostra applicazione attraverso il web. Oppure abbiamo bisogno del codice per parlare con un database in modo che i nostri dati vengano archiviati in modo persistente. Il codice per far funzionare effettivamente ogni porta è chiamato Adapter. Scriviamo almeno un Adapter per ogni porta della nostra applicazione.
Gli Adapters, che sono molto concreti e contengono codice di basso livello, sono per definizione disaccoppiati dalle loro porte, che sono molto astratte e, in sostanza, solo concetti. Poiché il codice dell’Adapter riguarda il collegamento di un'applicazione al mondo esterno, il codice dell'Adapter è un codice di infrastruttura e deve quindi risiedere nel livello dell'infrastruttura. Ed è qui che le porte e gli adattatori e l'architettura a strati giocano bene insieme.
PORTS AND ADAPTER
| 2 tipi di adapters
Gli Adapters sul lato sinistro, che rappresentano l'interfaccia utente, sono denominati Primary o Driving Adapters perché sono quelli che avviano un'azione sull'applicazione. il Primary Adapter rappresenta l'interfaccia utente. Questo può essere il nostro controller API, controller Web o le viste. Vengono chiamati Adapter di guida perché guidano l'applicazione e avviano azioni nell'applicazione principale. Questi Adapters possono utilizzare le porte in entrata (interfacce) fornite dall'applicazione principale. I controller quindi dipendono da queste interfacce.
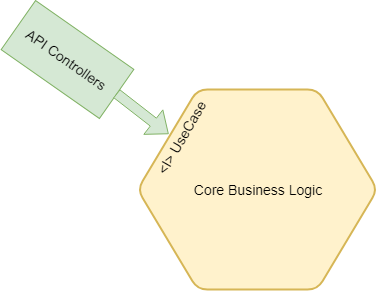
PORTS AND ADAPTER
| 2 tipi di adapters
Gli Adapters sul lato destro, che rappresentano le connessioni agli strumenti di back-end, sono chiamati Secondary o Driven Adapters perché reagiscono sempre all'azione di un Primary Adapter. I Secondary Adapters rappresentano la connessione ai database di back-end, alle librerie esterne, alle API di posta, ecc. I Secondary Adapters sono implementazioni della porta in uscita che in cambio dipendono dalle interfacce di queste librerie e strumenti esterni per trasformarle, quindi l'applicazione di base può usarle senza essere accoppiata a esse.
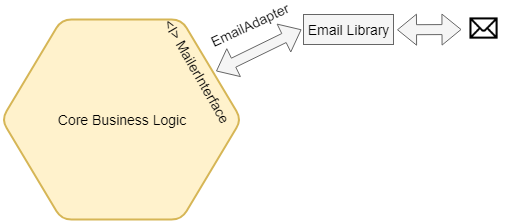
PORTS AND ADAPTER
| layers
Il livello più interno è il livello del dominio. Questo livello contiene tutta la business logic e definisce in che modo il livello esterno può interagire con esso. La business logic è fondamentale per l’applicazione, si potrebbe dire che il dominio è l’applicazione, e questa applicazione è technology agnostic. Il livello del dominio e la sua business logic definiscono il comportamento e i vincoli dell’applicazione. È ciò che rende la tua applicazione diversa dalle altre. È ciò che dà valore alla tua applicazione.
DOMAIN
Appena fuori dal Domain Layer si trova il livello Application. Questo livello orchestra l'uso delle entità del livello di dominio. Adatta anche le richieste esterne al Domain Layer in quanto si trova nel mezzo. Questo livello rappresenta lo strato esterno del codice che costituisce l'applicazione.
APPLICATION
framework (infrastructure)
Si trova fuori dall’Application Layer. Contiene il codice utilizzato dall'applicazione ma non è effettivamente la tua applicazione. Questo è spesso rappresentato dal framework o da come, per una specifica tecnologia, è necessario implementare i concetti di dominio o di applicazione. Ma può anche includere librerie di terze parti, SDK o altro codice usato (Pensa a tutte le librerie che porti con Composer).
PORTS AND ADAPTERS
| interfacce
Puoi pensare a un'interfaccia come contratto, che definisce le necessità di un'applicazione. Se l'esigenza dell'applicazione può essere o deve essere soddisfatta da più implementazioni, è possibile utilizzare un’interfaccia. L'interfaccia garantisce che siano disponibili metodi particolari per la nostra applicazione, indipendentemente dall'implementazione in cui è stata decisa. Ad esempio, se la nostra applicazione invia notifiche, potremmo definire un'interfaccia di notifica. Quindi possiamo implementare un notifier con Amazon SES o Mandrill.
interface Notifier {
public function notify(Message $message);
}
Sappiamo che qualsiasi implementazione di questa interfaccia deve avere il metodo notify(). In questo modo definiamo l'interfaccia come una dipendenza in altri punti della nostra applicazione. L'applicazione non si preoccupa di quale implementazione utilizza. Gli interessa solo che il metodo notify() esista per poterlo utilizzare.
PORTS AND ADAPTERS
| interfacce
class SomeClass {
public function __construct(Notifier $notifier)
{
$this->notifier = $notifier;
}
public function doStuff()
{
$to = 'some@email.com';
$body = 'This is a message';
$message = new Message($to, $body);
$this->notifier->notify($message);
}
}
La classe SomeClass non definisce un'implementazione specifica, ma richiede semplicemente una sottoclasse di Notifier. Questo significa che possiamo usare Amazon SES (Simple Email Service) o Mandrill o qualsiasi altra implementazione. Ciò evidenzia un modo importante in cui le interfacce possono aggiungere manutenibilità alla tua applicazione: possiamo semplicemente aggiungere una nuova implementazione.
PORTS AND ADAPTERS
| interfacce
class SesNotifier implements Notifier {
public function __construct(SesClient $client)
{
$this->client = $client;
}
public function notify(Message $message)
{
$this->client->send([
'to' => $message->to,
'body' => $message->body]);
}
}
// Usiamo SES
$sesNotifier = new SesNotifier(...);
$someClass = new SomeClass($sesNotifier);
// Oppure usiamo Mandrill
$mandrillNotifier = new MandrillNotifier(...);
$someClass = new SomeClass($mandrillNotifier);
// Funzionerà indipendentemente dall’implementazione
$someClass->doStuff();
PORTS AND ADAPTERS
| interfacce
class SesNotifier implements Notifier {
public function __construct(SesClient $client, Logger $logger)
{
$this->logger = $logger;
$this->client = $client;
}
public function notify(Message $message)
{
$this->logger->logMessage($message);
$this->client->send([...]);
}
}Aggiungere il logger direttamente all'implementazione concreta può andare bene, ma la nostra implementazione sta facendo due cose invece di una:
Ora, e se avessimo bisogno di aggiungere qualche funzionalità attorno alle implementazioni individuali (o tutte)? Ad esempio, potrebbe essere necessario aggiungere la registrazione alla nostra implementazione di SEE, forse per aiutare a risolvere un problema che stiamo riscontrando. Il modo più ovvio, ovviamente, è aggiungere il codice direttamente alle implementazioni.
PORTS AND ADAPTERS
| interfacce
class NotifierLogger implements Notifier {
public function __construct(Notifier $next, Logger $logger)
{
$this->next = $next;
$this->logger = $logger;
}
public function notify(Message $message)
{
$this->logger->logMessage($message);
return $this->next->notify($message);
}
}Stiamo mescolando gli aspetti (inviamo e notifichiamo). Inoltre se dovessimo aggiungere la registrazione a tutte le implementazioni ci troveremmo con codice molto simile in ogni implementazione. Un cambiamento nel modo in cui aggiungiamo la registrazione significa apportare modifiche a ciascuna implementazione. Per farla "pulita", possiamo utilizzare il pattern Decorator. Questo fa un uso intelligente delle interfacce per "avvolgere" una classe di decorazione attorno a un'implementazione al fine di aggiungere la nostra funzionalità.
Il bello è che la classe SomeClass non si preoccupa di essere passata in un oggetto decorato. Il decoratore implementa anche l'interfaccia prevista, quindi i requisiti impostati da SomeClass sono ancora soddisfatti!
PORTS AND ADAPTERS
| interfacce
Le interfacce sono il modo centrale per incapsulare il cambiamento. Possiamo aggiungere funzionalità creando una nuova implementazione e possiamo aggiungere comportamenti alle implementazioni esistenti, il tutto senza intaccare altre parti del codice.
La creazione di interfacce per parti della nostra applicazione che potrebbero cambiare è un modo per incapsulare il cambiamento. Possiamo creare nuove implementazioni o aggiungere ulteriori funzionalità attorno a un'implementazione esistente.
Dependency inversion principle
Nella programmazione orientata agli oggetti, il principio di inversione delle dipendenze (DIP) è una tecnica di disaccoppiamento dei moduli software, che consiste nel rovesciare la pratica tradizionale secondo cui i moduli di alto livello dipendono da quelli di basso livello. Il principio fu formulato per la prima volta da Robert C. Martin, che lo sintetizzò nel seguente modo:
I moduli di alto livello non devono dipendere da quelli di basso livello. Entrambi devono dipendere da astrazioni; Le astrazioni non devono dipendere dai dettagli; sono i dettagli che dipendono dalle astrazioni.
Il principio di inversione delle dipendenze è uno dei cinque principi SOLID della programmazione a oggetti. Nella sua presentazione del principio, Martin lo descrisse come una generalizzazione dell'applicazione combinata di altri due principi SOLID, il principio aperto/chiuso (O) e il principio di sostituzione di Liskov (L).
RISORSE
-
https://matthiasnoback.nl/2017/07/layers-ports-and-adapters-part-1-introduction/
-
https://github.com/matiux/hexagonal-architecture